SSH チートシート
たまに使うけど忘れがちなコマンド & tips についてメモ。
新しく生まれ変わった Easy Menu をお試しください
Easy Menu とは、設定ファイルを元にターミナル上で動作するコマンドランチャーを立ち上げるだけの、とてもシンプルなツールです。
実に 2 年以上の間ずっと放置していたのですが意外と社内で好評でしたので、この際リニューアルしてみました。
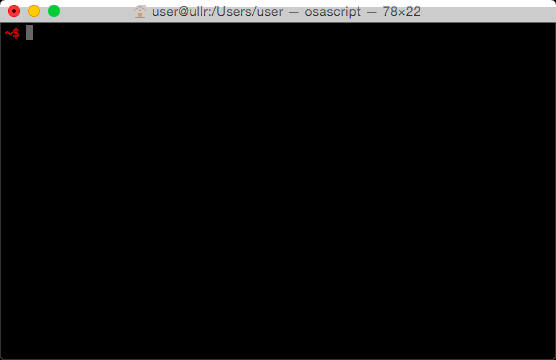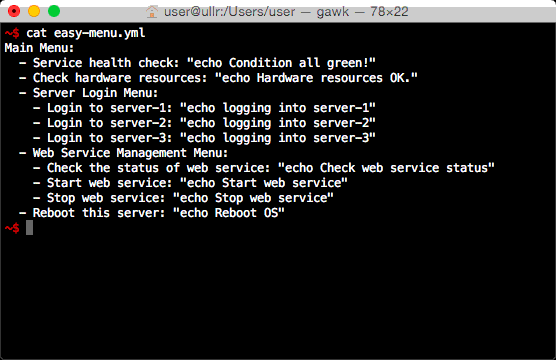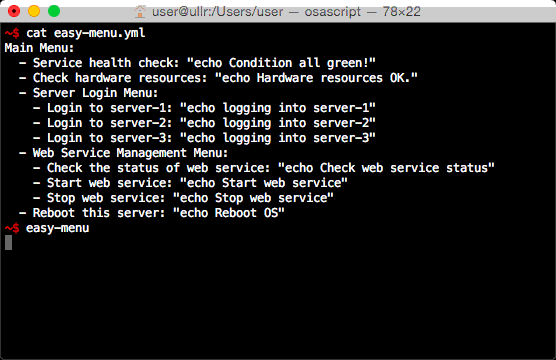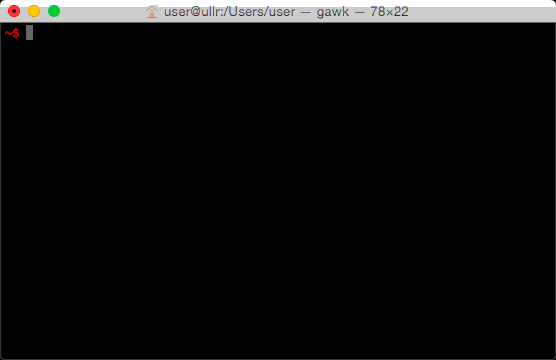
今回、パッケージを PyPI に登録することができたので、インストールがとても簡単になりました。
設定ファイルを HTTP(S) 経由で取得すれば、たった 2行のコマンドで Easy Menu をお試しいただけます。
注意: 2015-08-31時点では、まだ Python 3.x系には対応していません
=> 2015-09-02 にリリースした v1.0.2 で Python 3.2/3.3/3.4 に対応しました
pip install easy-menu easy-menu http://git.io/vGWla
前述のとおり、pip コマンドでインストールできるようになりました。
これまでは JSON のみのサポートでしたが、YAML にも対応しました。
"include" というキーワードを使うことで、別のファイルのメニューをマージすることが可能になりました。
設定イメージ:
---
メインメニュー:
- include: common.yml
- サブメニュー:
- コマンド3: echo 3
- コマンド4: echo 4
--- 共通メニュー: - コマンド1: echo 1 - コマンド2: echo 2
この場合、以下のようにメニューが生成されます。
---
メインメニュー:
- 共通メニュー:
- コマンド1: echo 1
- コマンド2: echo 2
- サブメニュー:
- コマンド3: echo 3
- コマンド4: echo 4
"eval" というキーワードを使うことで、任意のコマンドをメニュー生成時に実行し、その標準出力を YAML 形式の設定として読み込むことが可能になりました。
設定イメージ:
--- メインメニュー: - eval: scripts/create_ec2_menu.sh
この場合、シェルスクリプト create_ec2_menu.sh の出力がそのままメニューの内容として反映されます。
例えば、AWS で起動中の EC2 インスタンスの一覧を動的に取得するような使い方を想定しています。
現状、対応しているのは英語と日本語のみです。
以上、簡単な機能の紹介でした。
不具合、要望などがありましたら、お気軽に GitHub Issue に登録をお願いします。
Kubernetes を使って Spark クラスタを立ち上げる
適当なプロジェクト用ディレクトリに移動し、以下のコマンドを実行。
$ export KUBERNETES_PROVIDER=vagrant $ curl -sS https://get.k8s.io | bash
早速コケた。
Downloading kubernetes release v1.0.3 to /proj/mogproject/example-spark/kubernetes.tar.gz
--2015-08-23 10:39:46-- https://storage.googleapis.com/kubernetes-release/release/v1.0.3/kubernetes.tar.gz
Resolving storage.googleapis.com... 216.58.220.176
Connecting to storage.googleapis.com|216.58.220.176|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 121767360 (116M) [application/x-tar]
Saving to: ‘kubernetes.tar.gz’
100%[===============================================================================>] 121,767,360 1.76MB/s in 65s
2015-08-23 10:40:51 (1.80 MB/s) - ‘kubernetes.tar.gz’ saved [121767360/121767360]
Unpacking kubernetes release v1.0.3
Creating a kubernetes on vagrant...
Starting cluster using provider: vagrant
... calling verify-prereqs
... calling kube-up
Using credentials: vagrant:vagrant
Bringing machine 'master' up with 'virtualbox' provider...
Bringing machine 'minion-1' up with 'virtualbox' provider...
==> master: Box 'kube-fedora21' could not be found. Attempting to find and install...
master: Box Provider: virtualbox
master: Box Version: >= 0
Request for box's Amazon S3 region was denied.
This usually indicates that your user account with access key ID
is misconfigured. Ensure your IAM policy allows the "s3:GetBucketLocation"
action for your bucket:
arn:aws:s3:::opscode-vm-bento
どうやら vagrant up コマンドに失敗している模様。
認証周りを管理しているプラグイン vagrant-s3auth をアンインストールしたら、先に進んだ。
$ vagrant plugin uninstall vagrant-s3auth
しかし、今度はこの画面から一向に進まない。
Waiting for each minion to be registered with cloud provider ..................................................................
1時間待っても、2時間待っても状況変わらず。
どうやら、こちらの certificate 関連の厄介な問題に直面したようだ。
解決策は、1個前のバージョンである v1.0.1 にこちらのパッチを適用し、手動でインストールせよ、とのこと。
まずは VM を初期化。
$ cd kubernetes $ vagrant destroy -f $ vagrant box remove kube-fedora21 $ cd .. $ rm -rf ./kubernetes
Version 1.0.1 を手動でダウンロードしてから、パッチを適用。その後、インストール。
$ curl -LO https://github.com/kubernetes/kubernetes/releases/download/v1.0.1/kubernetes.tar.gz $ tar zxvf ./kubernetes.tar.gz $ cd kubernetes/cluster/vagrant $ curl -O https://raw.githubusercontent.com/kubernetes/kubernetes/release-1.0/cluster/vagrant/provision-master.sh $ curl -O https://raw.githubusercontent.com/kubernetes/kubernetes/release-1.0/cluster/vagrant/provision-minion.sh $ cd ../.. $ export KUBERNETES_PROVIDER=vagrant $ ./cluster/kube-up.sh
10分ほどで正常終了。ここまで長かった。
Cluster validation succeeded Done, listing cluster services: Kubernetes master is running at https://10.245.1.2 KubeDNS is running at https://10.245.1.2/api/v1/proxy/namespaces/kube-system/services/kube-dns KubeUI is running at https://10.245.1.2/api/v1/proxy/namespaces/kube-system/services/kube-ui
API との疎通確認
$ ./cluster/kubectl.sh get pods NAME READY STATUS RESTARTS AGE
Spark マスターサービスの起動
$ ./cluster/kubectl.sh create -f ./examples/spark/spark-master.json $ ./cluster/kubectl.sh create -f ./examples/spark/spark-master-service.json
暫く経つと Running になる。
$ ./cluster/kubectl.sh get pods NAME READY STATUS RESTARTS AGE spark-master 0/1 Pending 0 1m $ ./cluster/kubectl.sh get pods NAME READY STATUS RESTARTS AGE spark-master 1/1 Running 0 15m $ ./cluster/kubectl.sh logs spark-master
Spark ワーカーの起動
$ ./cluster/kubectl.sh create -f examples/spark/spark-worker-controller.json
15分経っても、3個中2個は Pending のままだった。
$ ./cluster/kubectl.sh get pods NAME READY STATUS RESTARTS AGE spark-master 1/1 Running 0 34m spark-worker-controller-6cgpd 0/1 Pending 0 15m spark-worker-controller-tqa4b 0/1 Pending 0 15m spark-worker-controller-yl7n2 1/1 Running 0 15m $ ./cluster/kubectl.sh get services NAME LABELS SELECTOR IP(S) PORT(S) kubernetes component=apiserver,provider=kubernetes 10.247.0.1 443/TCP spark-master name=spark-master name=spark-master 10.247.70.164 7077/TCP $ ./cluster/kubectl.sh get nodes NAME LABELS STATUS 10.245.1.3 kubernetes.io/hostname=10.245.1.3 Ready
spark-master の IPアドレスとポートを確認。
$ ./cluster/kubectl.sh get service spark-master NAME LABELS SELECTOR IP(S) PORT(S) spark-master name=spark-master name=spark-master 10.247.70.164 7077/TCP
Kubernetes の minion-1 にログインし、適当な Docker コンテナを起動。
その中で、環境変数や /etc/hosts ファイルを書き換えるユーティリティ用スクリプト setup_client.sh を(同一シェル内で)実行。
[vagrant@kubernetes-minion-1 ~]$ sudo docker run -it gcr.io/google_containers/spark-base root@49cc6b98cb5f:/# . /setup_client.sh 10.247.70.164 7077
Kubernetes 上の Spark クラスタへアクセスしていることを確認できた。
root@49cc6b98cb5f:/# spark-shell
15/08/23 11:04:18 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (OpenJDK 64-Bit Server VM, Java 1.7.0_79)
Type in expressions to have them evaluated.
Type :help for more information.
Spark context available as sc.
15/08/23 11:04:31 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
15/08/23 11:04:33 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
15/08/23 11:04:43 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 0.13.1aa
SQL context available as sqlContext.
scala> sc.isLocal
res0: Boolean = false
scala> sc.master
res1: String = spark://spark-master:7077
Python の API で、Spark ワーカーのホスト名を取得してみる。
root@49cc6b98cb5f:/# pyspark
Python 2.7.9 (default, Mar 1 2015, 12:57:24)
[GCC 4.9.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
15/08/23 11:12:06 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Python version 2.7.9 (default, Mar 1 2015 12:57:24)
SparkContext available as sc, HiveContext available as sqlContext.
>>> import socket
>>> sc.parallelize(range(1000)).map(lambda x:socket.gethostname()).distinct().collect()
['spark-worker-controller-yl7n2']
NetworkX のグラフジェネレーターで遊ぶ
out-of-the-box な機能が非常に豊富で感動した。
せっかくなので、IPython Notebook でビジュアライズしてみる。
全て必須という訳ではないが、一応インストールしておく。
pip install ipython jinja2 tornado pyzmq numpy scipy pylab matplotlib pip install networkx
作業ディレクトリに移動して、IPython Notebook 起動。
ipython notebook
ブラウザ上で操作し、 New Notebook を作成。
コードの補完もできる。
ひととおりグラフを作ったあと保存し、そのファイルを Gist にアップロードしてみた。
すると以下のとおり、簡単にコードとイメージを共有することができる。
このカジュアルさに、また感動。Python 素晴らしい。
Python: set を要素に持つ set を書く
普通に書くと、unhashable type (ハッシュ化できないデータ型) だと怒られる。
>>> {set(), {1}, {1, 2}}
Traceback (most recent call last):
File "", line 1, in
TypeError: unhashable type: 'set'
内側の set(集合) に frozenset を使えばよい。
>>> {frozenset(), frozenset({1}), frozenset({1, 2})}
{frozenset({1, 2}), frozenset(), frozenset({1})}
fronzenset はイミュータブルなので、後から変更を加えることはできない。
>>> s = frozenset() >>> s.add(1) Traceback (most recent call last): File "", line 1, in AttributeError: 'frozenset' object has no attribute 'add'
Shell: 安全にファイルの内容を入力と同時に書き換える
同僚に教えてもらった。
一見、本当に安全なのかわかりづらいが、結果、大丈夫そう。
(rm -f -- "${FILEPATH}" && COMMAND > "${FILEPATH}") < "${FILEPATH}"
これで、一時ファイルなしでファイルを入力しながら書き出すことが可能になる。(inode は変わる)
CircleCI がキャッシュ復元処理の後で失敗した
CircleCI を回していたら、Restore cache の後でエラー終了となってしまった。
画面には以下のようなメッセージが出現している。
Looks like we had a bug in our infrastructure, or that of our providers (generally GitHub or AWS) We should have automatically retried this build. We've been alerted of the issue and are almost certainly looking into it, please contact us if you're interested in the cause of the problem.
チャットでサポートに連絡したら、なんと 30分で回答が返ってきた。
We currently can’t cache files outside the home directory. E.g. they will be cached, but the build will err out on restoring the cache. I see that you are caching a few files in /usr/local, would that be an option for you to store them in the home directory, cache them and then symlink them into the right place?
実は今回、circle.yml で /usr/local 配下のあるディレクトリをキャッシュ対象として指定していた。
現状ではホームディレクトリ以外の場所はキャッシュできないようだ。
キャッシュ保存時は成功したように見えるが、復元の時点でエラーが発生するとのこと。
対応策としては、ホームディレクトリ配下にキャッシュ用のディレクトリを作って、そこにシンボリックリンクを張るとよいと教えてもらった。
後日対応し、問題なく稼動している。
dependencies:
pre:
- sudo mkdir -p yyyyy /usr/local/lib/xxxxx
- sudo ln -s $PWD/yyyyy /usr/local/lib/xxxxx/yyyyy
StackShare でもカスタマーサポートが良いと好評だが、それを実感することができてよかった。
CircleCI については、こんなものも書きました。

